Sommaire
- Présentation
- Qu’est ce que s’est l’automatisation ?
- Qu’est ce que c’est Ansible ?
- Comment ça fonctionne ?
- Mon travail
Présentation
Ici le projet porte sur l’automatisation du système d’installation et de configuration des environnements CARDABEL (OS + Application) avec toutes les dépendances nécessaires en supprimant la contrainte de versionning des plug-ins et logiciels, sur les différents profils (administrateur, développeur et production).
Qu’est-ce que c’est l’automatisation ?
L’automatisation informatique fait référence à l’utilisation des technologies et d’outils pour exécuter automatiquement des tâches, des processus ou des opérations dans le domaine de l’informatique. Elle vise à rationaliser les opérations informatiques en réduisant la dépendance à l’égard des tâches manuelles, en améliorant l’efficacité et en permettant aux équipes informatiques de se concentrer sur des tâches à plus forte valeur ajoutée. L’automatisation est réalisée en utilisant divers outils, tels que des scripts, des langages de programmation, des outils d’orchestration, des outils de gestion de configuration, des systèmes de surveillance, des plateformes de conteneurisation, des outils de déploiement d’applications.
Qu’est ce que c’est Ansible ?
Ansible est apprécié pour sa simplicité, sa facilité d’apprentissage et sa polyvalence. C’est un outil d’automatisation open source très utilisé pour la gestion de la configuration, le déploiement d’applications, l’orchestration et l’automatisation des tâches informatiques. il permet de décrire les états souhaités des systèmes et des infrastructures de manière déclarative, puis de les mettre en œuvre de manière cohérente sur un ensemble de nœuds cibles.
Comment ça fonctionne ?
Ansible adopte une approche déclarative qui permet de décrire l’état souhaité du système plutôt que de spécifier des étapes détaillées pour l’atteindre. Ansible utilise YAML (Yet Another Markup Language) pour décrire les configurations et les tâches. Le YAML est un format lisible par les humains, facile à comprendre et à écrire, ce qui le rend accessible aux développeurs et aux opérationnels. Il permet de traiter l’infrastructure et les configurations systèmes comme du code en gérant l’infrastructure en utilisant des fichiers textes « versionnés », les partager et les réutiliser facilement. Les playbooks sont des fichiers YAML qui décrivent les rôles, les tâches et les configurations à exécuter sur les nœuds cibles. Les playbooks permettent de regrouper des tâches liées, de définir des dépendances et de spécifier des variables.
Mon travail :
projet : Automatisation de l’environnement CARDABEL
Lors de ce projet, j’ai mis en place un système automatisé d’installation des outils nécessaires pour le bon fonctionnement de l’application en réadaptant les scripts PowerShell en YAML sous forme de playbooks afin d’avoir les mêmes fonctionnalités.
Etape 1 : Installation des dépendances
Pour l’exécution de mon projet j’ai dû installer plusieurs programmes en amant de l’installation de ansible notamment python, du fait que ansible est écrit en python donc celui-ci devient une dépendance de base de ansible; en plus de cela j’ai également installé SSH (Secure Shell) qui permet de se connecter aux nœuds cibles et d’exécuter des tâches à distance. En suite, les instructions d’installation varient en fonction du système d’exploitation que vous utilisez, dans mon cas l’installation de ansible s’est fait sur Debian avec la commande « apt install ansible ». Il est recommandé de consulter la documentation officielle d’Ansible pour obtenir des instructions d’installation détaillées et spécifiques à votre système d’exploitation.
Etape 2 : Configuration et création d’arborescence
Après l’installation des dépendances et de ansible, j’ai dû configurer le fichier ansible.cfg pour signifier le fichier dans lequel les nœuds se trouvent sous forme d’adresse IP et le chemin vers la clé SSH à utiliser pour établir la connexion.

Ensuite, j’ai eu à créer un dossier contenant l’ensemble de mes fichiers de configuration (configuration de nœuds, différenciation des profils, playbooks, information de connexion, …).
Etape 3 : Ecriture des playbooks
Mes playbooks, qui constituent la plus grande partie de cet exercice du fait qu’ils représentent 95% de tout ce travail, déterminent l’ensemble des actions à mener en fonction des étapes à faire pour la bonne exécution de l’application. Dans mon projet, j’en ai écrit plusieurs regroupés en deux catégories: script (qui regroupe des commandes à exécuter dans le PowerShell de la machine distante une fois celle-ci connectée) et yaml (qui contient l’ensemble des logiciels, configurations, et actions que ansible prend en charge sur ladite machine distante).

Etape 4 : Teste de l’exécution sur les machines distantes
Une fois tous les playbooks écrits, l’exécution se fait en fonction du profil. Dans mon cas, ayant beaucoup travaillé sur les profils développeur, l’exécution d’un playbook donne cet aperçu :
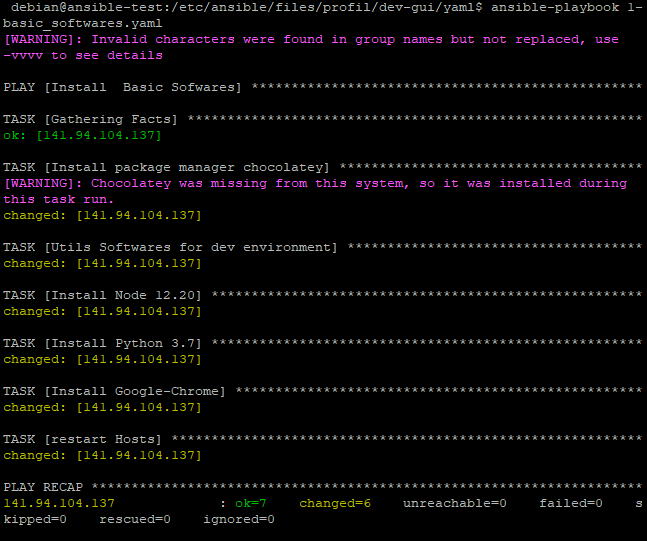
Résumé :
| Ce que j’ai appris | – scipting en YAML et Powershell – installation distant des services sur un environnement |
| Résultat | – gestion fonctionnelle des noeuds distants – gestion des versions sur différents systèmes |
| synthèse | je projet m’a permis de comprendre le système d’automatisation des actions répétitives ou non en entreprise, en misant sur le gain de temps. |